webスクレイピング
enebularの公式プライベートノード、web-scrapingはwebスクレイピング機能を提供しています。
webスクレイピング機能では、フローエディターまたはクラウド実行環境からヘッドレスブラウザ制御ライブラリPuppeteerを用いたwebスクレイピングを実行できます。
このチュートリアルでは、プライベートノードとサンプルフローをインポートし、フローを実行してウフルのコーポレートサイトにあるニュースページからニュースのタイトルとリンクのリストを取得します。(所要時間10分)
※1 webスクレイピング機能はエンタープライズプラン、トライアルプラン限定の機能です。
※2 webスクレイピング機能はエージェント実行環境、enebular Editorからは利用できません。
Puppeteerについてのより詳細な情報は、Puppeteer公式ドキュメントを参照してください。
Table of Contents
プライベートノードのインポート
Discover Assetsから、webスクレイピングを実行するためのプライベートノードをインポートする手順を説明します。
enebularの画面右上にあるDiscover Assetsをクリックしてください。
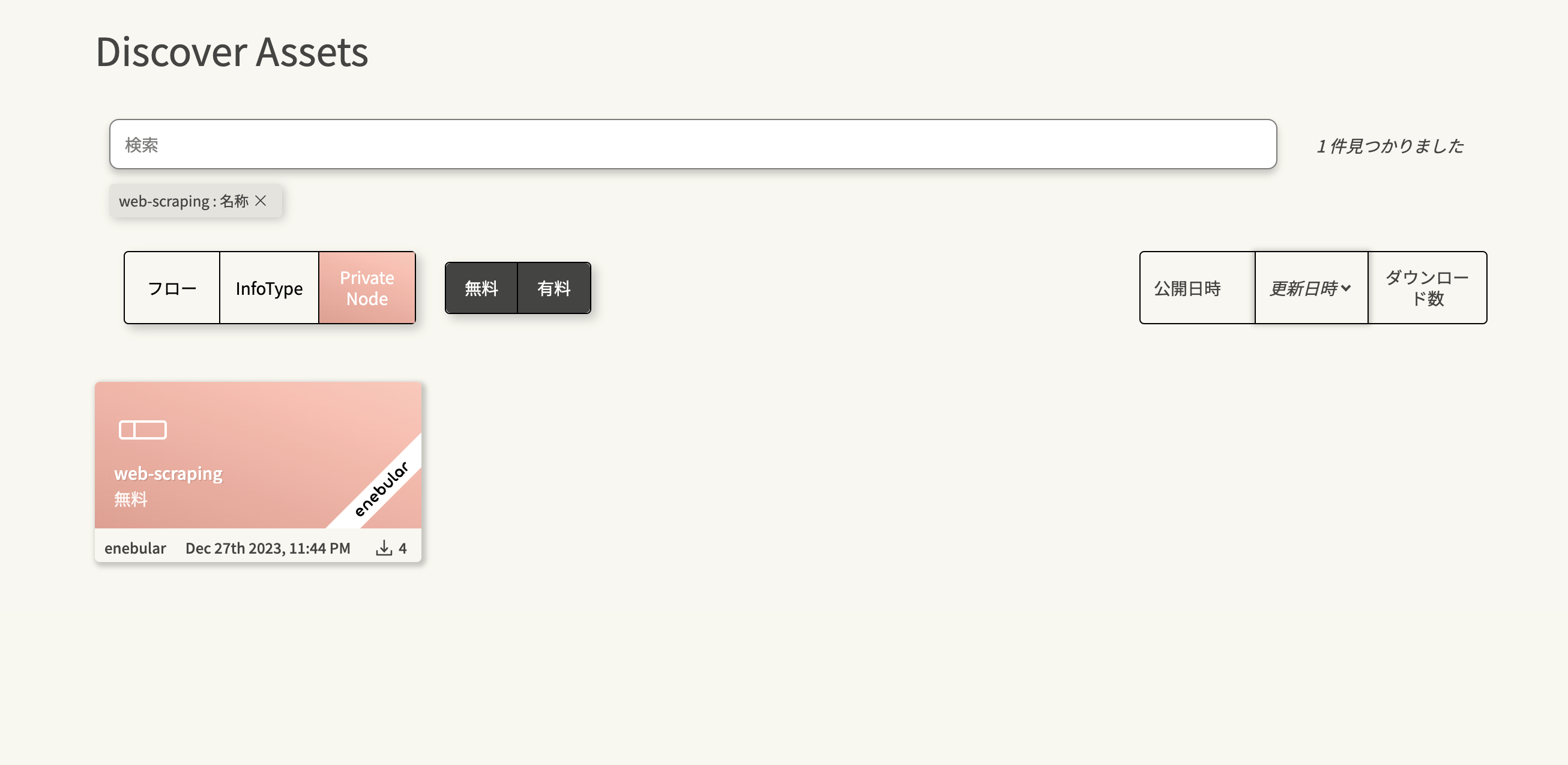
以下の手順でプライベートノードweb-scrapingを検索します。
- アセットの種類で
Private Nodeを選択します - 検索バーに
web-scrapingと入力します - プルダウンから
名称を選択します
検索結果に表示されるenebularのラベルがついたプライベートノードをクリックしてください。
インポートをクリックします。
インポート先のプロジェクトを選択し、インポートをクリックしてください。これでプライベートノードのインポートは完了です。インポート先として選択したプロジェクトのアセット一覧画面で、プライベートノードが追加されたことを確認してください。
サンプルフローのインポート
インポートしたプライベートノード利用してwebスクレイピングを行うサンプルフローをプロジェクトにインポートする方法を説明します。
このサンプルフローはDiscover Assetsに公開しています。
サンプルフローを開く
サンプルフローについて説明します。
スクレイピング実行用コード
インポートしたフローを開きます。

webスクレイピングと表記されているノードを開くと、Puppeteer用コードとラベルのついたエディターが表示されます。
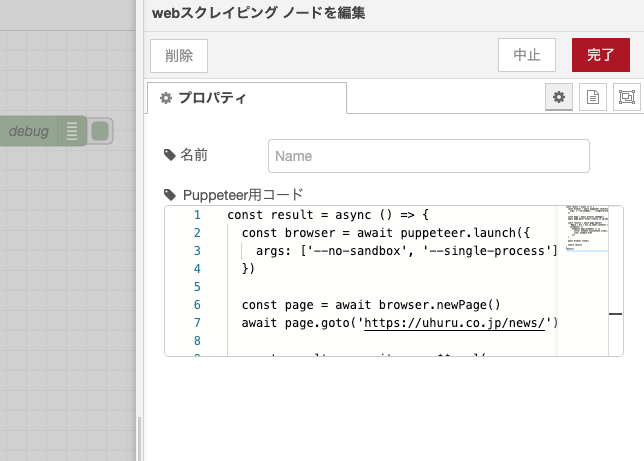
エディターにはウフルのコーポレートサイトにあるニュースページにアクセスし、最新のページに表示されているニュースのタイトルとリンクを取得するコードが入力されています。
const URL = "https://uhuru.co.jp/news/" // アクセスするURL
const SELECTOR = "#main > div > div.ly_under_contents > div > div.bl_newsList.hp_mt55.hp_sp_mt50 > div > div.bl_newsList_title > a" // セレクター
// 関数の定義
const scrapeNews = async () => {
// ブラウザーの起動
const browser = await puppeteer.launch({
args: ['--no-sandbox', '--single-process']
})
// ウフルニュースページへのアクセス
const page = await browser.newPage()
await page.goto(URL)
// ニュース一覧に存在するすべてのaタグからテキストとリンクを取得
const newsItems = await page.$$eval(
SELECTOR,
(elements) =>
elements.map((element) => ({
title: element.textContent,
link: element.href
}))
)
// ブラウザーの終了
await browser.close()
// 結果を返す
return newsItems
}
// 関数の実行
scrapeNews()
ブラウザーの起動
// ブラウザーの起動
const browser = await puppeteer.launch({
args: ['--no-sandbox', '--single-process']
})
puppeteerでブラウザーを起動します。ここで設定されている起動オプションは以下の通りです。
- --no-sandbox: Sandboxモードの無効化
- puppeteerが行う操作の制限を解除します
- --single-process: シングルプロセスモードでの起動
- すべてのページが同一のプロセスで実行されます
ブラウザーが正常に起動しない場合があるため、上記を必ず設定してください。
webページへのアクセス
// ウフルニュースページへのアクセス
const page = await browser.newPage()
await page.goto(URL)
pageオブジェクトを宣言し、ブラウザーのタブを操作できるようにします。
page.goto()メソッドにURLを渡すことで、任意のページにアクセスできます。
テキストとリンクの取得
// ニュース一覧に存在するすべてのaタグからテキストとリンクを取得
const newsItems = await page.$$eval(
SELECTOR,
(elements) =>
elements.map((element) => ({
title: element.textContent,
link: element.href
}))
)
ウフルニュースページに表示されている要素を取得します。page.$$evalメソッドは、セレクターの条件に合う要素をすべて取得するメソッドです。取得された各要素は評価関数である(elements) => elements.map((element) => ...)部分に渡され、mapメソッドにより配列を作成しています。element.textContentでは要素の持つテキストを、element.hrefでは要素の持つリンク先のURLを取得します。
セレクターの取得方法について
Google Chromeでセレクターを取得する例を紹介します。ここではウフルコーポレートサイトのニュースページ(https://uhuru.co.jp/news/)を例に行います。
Google Chromeウィンドウの右上にある三点マークをクリックし、メニューを開きます。その他のツールにカーソルを合わせ、メニューにデベロッパーツールが現れたらクリックします。
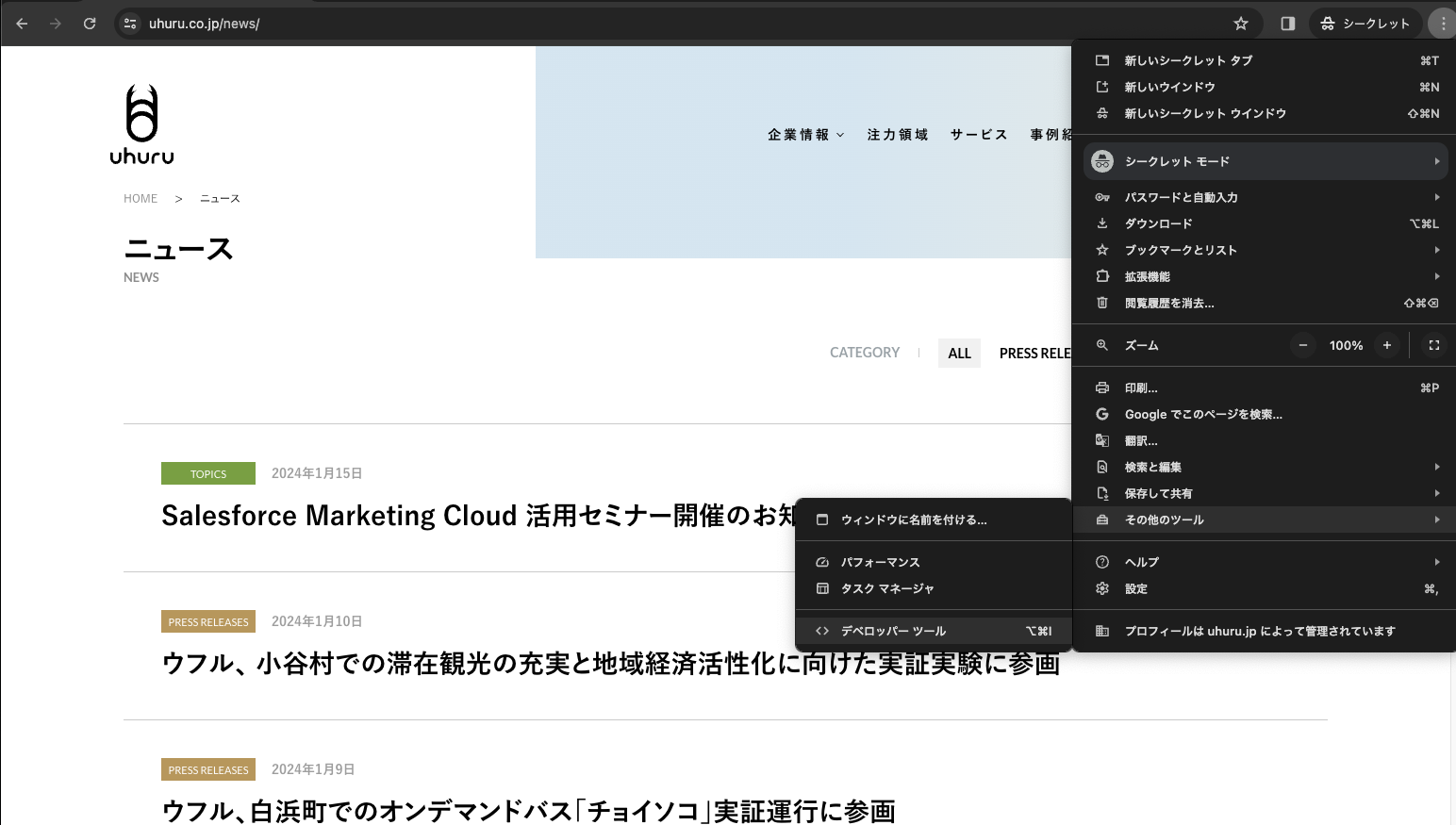
デベロッパーツールが画面に表示されます。Elementsタブが開いていることを確認し、左上にある矢印のついたアイコンをクリックします。この状態でページの要素にカーソルを合わせると、ポップアップに要素の詳細な情報が表示されます。
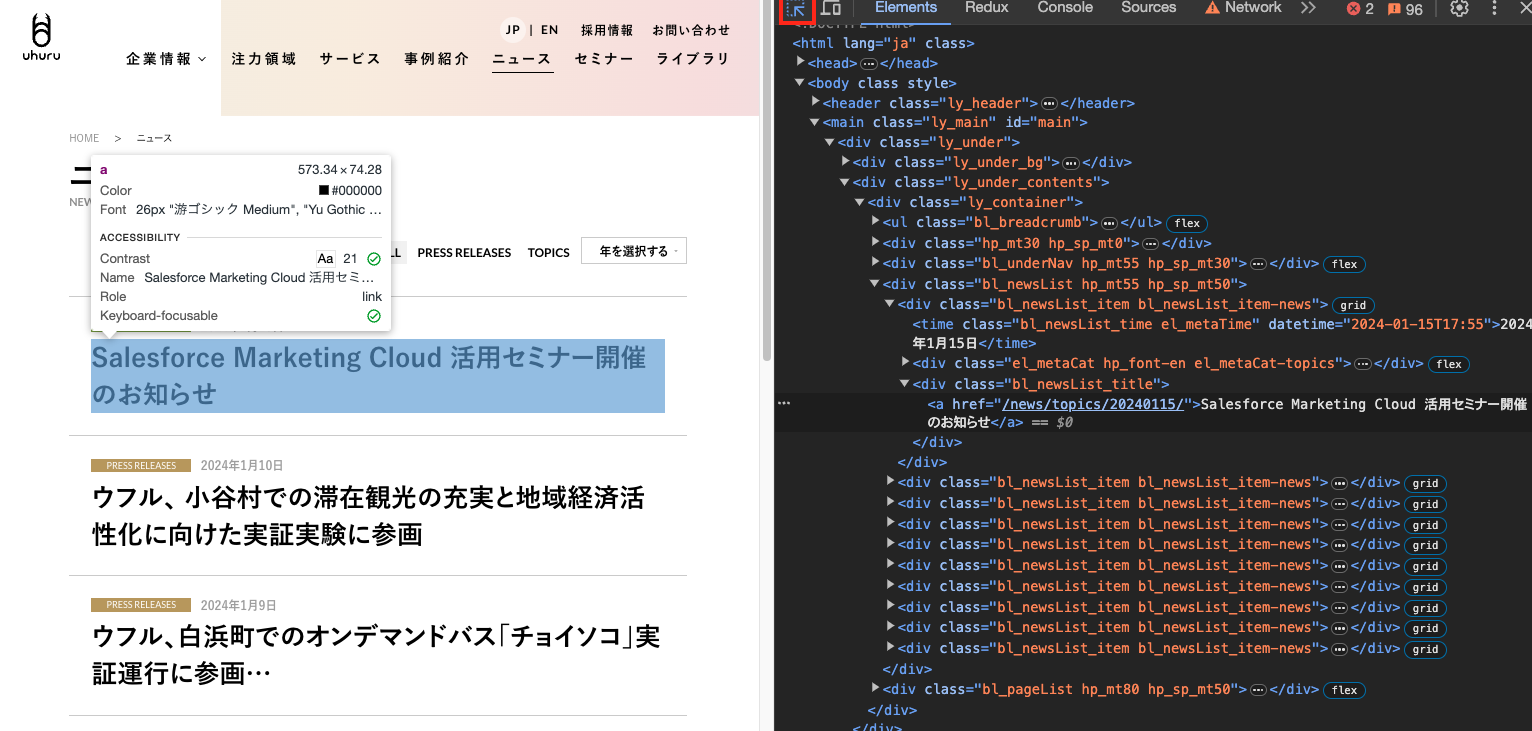
セレクターを取得したい要素にカーソルを合わせ、クリックします。デベロッパーツールに選択した要素のソースがフォーカスされるので、フォーカスされた箇所を右クリック→Copy→Copy selectorを選択すると、クリップボードにセレクターがコピーされます。
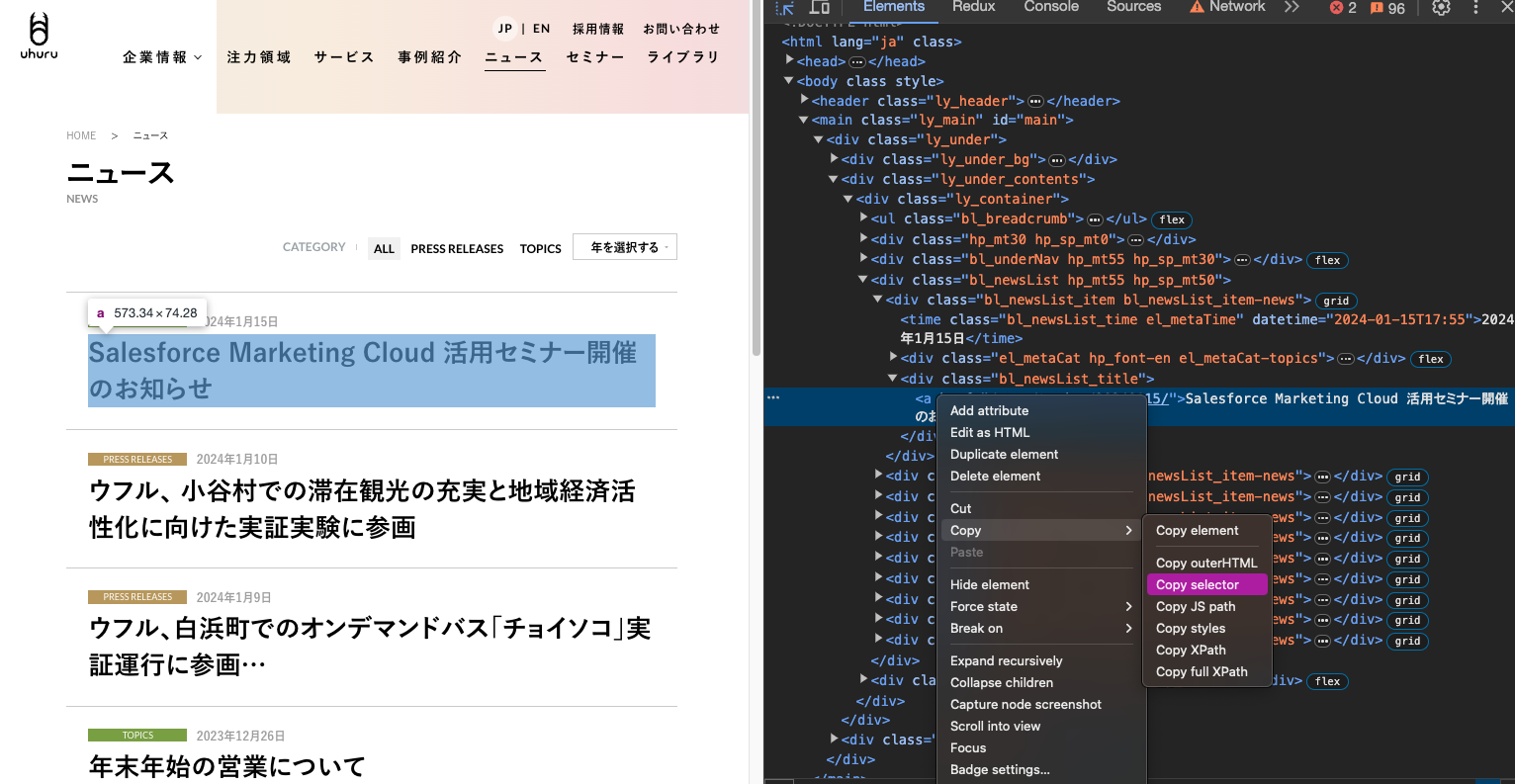
クリップボードにコピーされたセレクターは以下のようになっています。
#main > div > div.ly_under_contents > div > div.bl_newsList.hp_mt55.hp_sp_mt50 > div:nth-child(1) > div.bl_newsList_title > a
div:nth-child(1)から:nth-child(1)を削除します。
#main > div > div.ly_under_contents > div > div.bl_newsList.hp_mt55.hp_sp_mt50 > div > div.bl_newsList_title > a
これで条件に合致するすべての要素を指定できるセレクターとなりました。
Google ChromeはGoogle LLCの商標です。
ブラウザーの終了と結果の返却
// ブラウザーの終了
await browser.close()
// 結果を返す
return newsItems
コードの正常な実行のため、ブラウザーの終了を行なってください。
ノードに値を出力させるため、returnで返り値を定義してください。
サンプルフローの実行
タイムスタンプと表記されているノードのボタンをクリックし、フローを実行します。
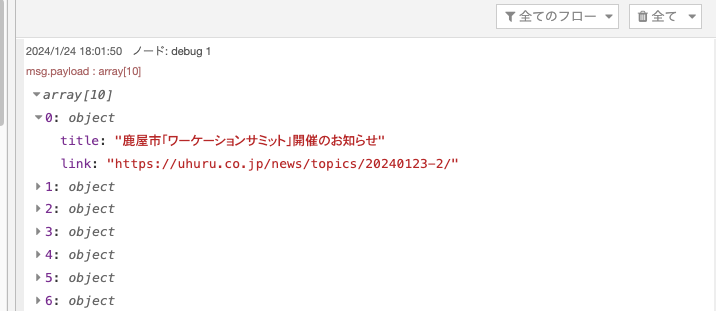
フローの実行が完了すると、デバッグメッセージに以下のような結果が出力されます。
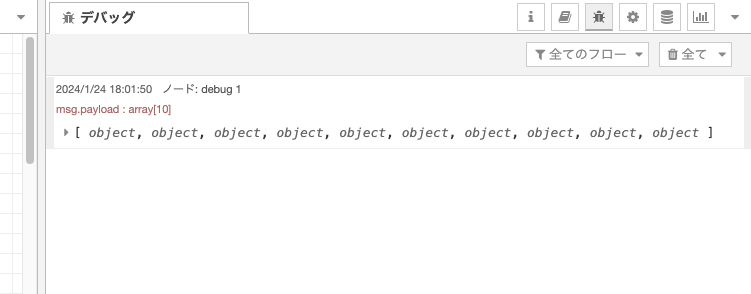
配列をクリックして展開すると、各オブジェクトが0: objectのように格納されています。
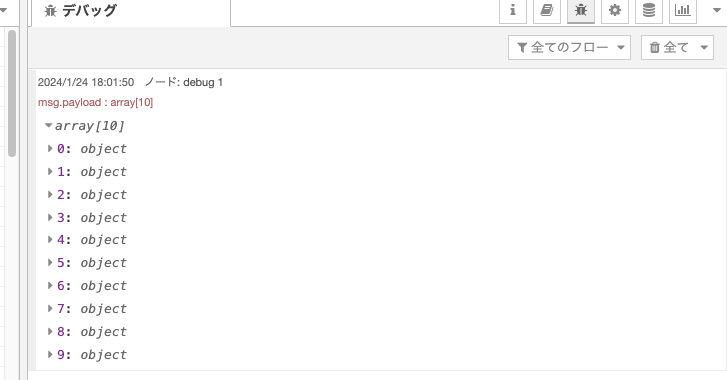
さらにクリックして展開すると、titleにニュースタイトル、linkにURLが格納されています。
Well Done!
サンプルフローを用いてenebularでwebスクレイピングが実行できました。クラウド実行環境での実行の際には、LCDPノードの追加およびクラウド実行環境設定ページでのwebスクレイピング利用設定を忘れずに行ってください。 クラウド実行環境でのwebスクレイピング利用設定は、クラウド実行環境の管理ページのwebスクレイピングの利用を参照してください。